


ReMEmbR shows how generative AI can help robots reason and act, says NVIDIA
Robotics Business Review
SEPTEMBER 28, 2024
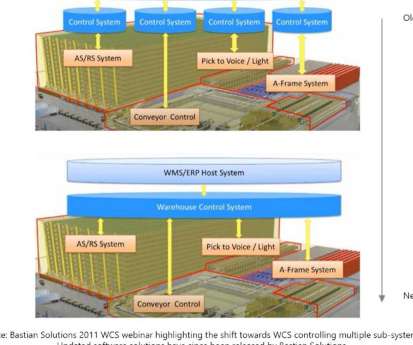
. | Source: NVIDIA Vision-language models, or VLMs, combine the powerful language understanding of foundational large language models with the vision capabilities of vision transformers ( ViTs ) by projecting text and images into the same embedding space. The full ReMEmbR system. Click here to enlarge.








Let's personalize your content